
顶刊TPAMI|多模态视频邻接领域重磅数据更新: MeViSv2发布

近日,多模态视频邻接领域迎来重磅更新!由复旦大学、上海财经大学、南洋理工大学鸠合打造的 MeViSv2 数据集老成发布,并已被顶刊 IEEE TPAMI 寄托。

论文:MeViS: A Multi-Modal Dataset for Referring Motion Expression Video Segmentation,TPAMI 2025
arXiv 邻接:https://arxiv.org/abs/2512.10945
单元:复旦大学、上海财经大学、南洋理工大学
动作现在该领域最具有代表性的数据集之一,MeViSv2 围绕复杂动作推理来挑战现存模子的多模态处理才调,其包含 2,006 个视频、8,171 个主义及 33,072 条规本 / 音频抒发,通过新增 15 万秒音频数据已毕了向原生多模态的进化。
该数据集不仅全面赞助 RVOS、RMOT、AVOS 以及 RMEG 四大中枢任务,更引入了 “无目口号句” 和 “畅通推理” 等机制,旨在挑战模子逻辑推理与鲁棒性的天花板。现在,数据集、代码及评测平台均已通达。

图 1:MeViS 示例,MeViS 中的抒发主要侧重于畅通属性,使得仅凭单帧图像无法识别主义对象。最新的 MeViSv2 进一步提供了畅通推理和无主义抒发式,同期给每一个文本提供了对应的音频记载。
MeViSv1:从 “静态特征识别” 到 “动态畅通邻接”
指向性视频分割(RVOS)是多模态视频邻接的迫切标的,频年备受眷注。依托天然谈话交互的机动性,RVOS 在具身智能、视频剪辑和辅助驾驶等领域展现出稠密的诈欺出息。然则,在 Refer-YouTube-VOS 和 DAVIS 等早期 RVOS 数据鸠合,研究东谈主员发现了一个 “隐形弱势”:主义物体时常具有了然于目的静态属性。模子只需看一眼单帧图像,依靠 “红穿戴”、“左边” 等静态陈迹就能锁定主义,完全忽略了视频动作 “时分序列” 的动态本体。
为了冲突这一局限,MeViS (Motion expressions Video Segmentation) 应时而生。其第一版 MeViSv1 便确立了探索像素级视频邻接的三大中枢绪念:
畅通优先 (Motion Priority):标注指南强制条件谈话抒发式必须侧重于时势对象的畅通陈迹(举例:奔走、航行、出动),而非静态特征,迫使模子必须眷留神频的时分动态信息。
复杂场景 (Complex Scenes):视频素材挑升选自复杂、多对象的场景,拒却 “通俗配景下的单一个体”,极大提高了辨识难度。
万古序关联 (Long-term Dependency):MeViS 视频的平均时长为 13.16 秒,主义物体平均延续时分长达 10.88 秒,远超同类数据集(时时仅约 5 秒)。这对模子邻接万古许动作以及处理相似物体间的万古许欺侮提倡了极高条件。
在这一理念下,MeViSv1 提供了异常 28,000 个高质料语句标注,掩饰 2,006 个视频中的 8,171 个物体 。如上图 1 的第一个样例所示,三只鹦鹉外不雅止境相似,静态特征失效,唯有邻接了 “The bird flying away” 这一动态时势,模子才能准折服位主义。限定现在,MeViSv1 在 CodaLab 上已眩惑环球近千支队列参预评测、累计 1 万余次提交,何况班师在 CVPR 2024、ECCV 2024、CVPR 2025、ICCV 2025 上举办环球挑战赛,眩惑了数百支来自国表里顶尖机构的队列参赛,这为 MeViSv2 的全面进化奠定了坚实基础。
MeViSv2:迈向更通用的原生多模态视频邻接
MeViSv2 在 MeViSv1 的基础上进行了权臣的彭胀和增强,尤其是在多模态数据方面,旨在提供一个更具挑战性、更逼近真实寰宇、掩饰多模态全场景的视频邻接研究平台。MeViSv2 的全体的联想遴选延续了 MeViSv1 数据集的挑战性,同期比拟于 MeViSv1,其有三个最大亮点:
1. 模态加多:音频赞助
MeViSv2 的一大亮点是初次为沿途的 33,072 个文本语句齐配对了对应的语音指示。这进一步拓展了多模态赞助,同期也记号着 MeViS 依然从视频数据集进化为原生多模态数据集。这些音频数据总时长异常 150,000 秒,源于几十位不同庚岁、性别和配景的真东谈主录制以及先进的 TTS 模子合成,保证了语音数据的各样性、天然性和真实感。
比拟于冷飕飕的文本,音频动作东谈主类领路的体现,在闲居交互中愈加天然、多量和方便。它承载着丰富的语义信息,并能捕捉到文本自身无法传达的语调、心情和重音等渺小隔离。这些特色有助于更精确的主义识别和分割。MeViSv2 中新加入的音频形势不仅赞助音频提示视频对象分割,还赞助确凿的多模态视频理辞退务,通过联结文本和音频两者的上风,多模态援用抒发在增强视频邻接以及赞助更天然、直不雅的交互方面提供了权臣的上风和机动性。
2. 任务更广:四大中枢任务
除了音频与分割掩码,MeViSv2 还系统性地补充了精确的物体轨迹标注,使其一跃成为迄今为止限制最大的指向性多主义跟踪 (RMOT) 数据集。凭借异常 33,000 条语句和 2,000 个视频的弘远体量,MeViSv2 为 RMOT 提供了远超现存基准的闇练数据,是研发下一代高精度多主义跟踪模子的理念念泥土。
总的来说,在多模态数据的全面加持下,MeViSv2 冲突了任务壁垒,仅凭单一数据集即可赞助多模态视频邻接领域的四大中枢任务:
指向性视频主义分割(RVOS,Referring Video Object Segmentation)
音频提示视频主义分割(AVOS,Audio-guided Video Object Segmentation)
指向性多主义跟踪(RMOT,Referring Multi-Object Tracking)
畅通指向性语句生成(RMEG,Referring Motion Expression Generation)
这些任务全场合掩饰了图像、音频、分割掩码、规模框以及生成式邻接等关节维度,确立了 MeViSv2 动作视频邻接领域首个确凿万能数据集的地位。
3. 限制增大:更具挑战性的语句类型与数目
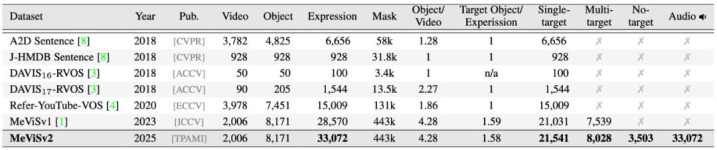
表 1:MeViSv2、MeViSv1 与其他多模态视频分割数据集对比。
MeViSv2 将总抒发式数目引申至 33,072 条,相较于 MeViSv1 新增了 4,502 条极具挑战性的语句。这一彭胀绝非通俗的数字堆砌,而是专为大模子时间量身定制,精确掩饰了刻下 AI 推理才调最中枢的两大挑战瓶颈:
畅通推理语句 (Motion Reasoning Expressions): 从 “看动作” 到 “懂因果” 这类语句不再直白时势动作,而是通过隐式查询条件模子进行复杂的逻辑推理。如图 2 (a) 所示:面对 “What is causing the cage to shake?” 的发问,模子弗成只寻找 “泛动的笼子”,而必须不雅察视频细节,算计出是笼内那只正在扑腾的鸟(橙色掩码)激发了回荡。如图 2 (b) 所示:关于 “The one whose life is being threatened” 这一时势,模子需要邻接狮子捕猎斑马的动态关系,才能准折服位到被追赶的斑马,而非捕食者。
无目口号句 (No-Target Expressions):拒却 “以白为黑”,为了惩办模子在主义不存在时仍强行输出的 “幻觉” 问题,MeViSv2 引入了具有糊弄性的无主义抒发 。如图 2 (c) 所示:语句时势 “Moving coins from right pile to left pile”,这看起来是一个相等具体的动作时势。但实验上,视频中的鹦鹉是叼起硬币从左边挪到右边,而非从右到左。如图 (b) 所示:语句接头 “The dog whose life is being threatened”,尽管视频中有厉害的追赶画面,但主角是斑马而非狗。面对这些极具误导性的时势,MeViSv2 条件模子具备 “判伪” 才调,在视频中莫得匹配对象时,刚硬地输出 “无主义”,从而极地面增强了现实诈欺中的鲁棒性。

图 2:MeViSv2 中新增的畅通推理语句和无目口号句示例。图中象征为橙色的物体为畅通推理语句的主义,而无目口号句是具有糊弄性,但不指代任何对象的语句。
LMPM++:大谈话模子启动的时序推理模子
面对 MeViSv2 带来的万古序依赖与复杂逻辑挑战,传统的基于 “关节帧采样” 或 “静态特征匹配” 的才能已显牛逼不从心。为此,该团队提倡了全新的基线才能:Language-guided Motion Perception and Matching (LMPM++)。如图 3 所示,LMPM++ 奥密地将大谈话模子 (LLM) 的推理才调引入了视频邻接,通过以下四大时间立异,灵验惩办了 “看不全”、“理不清” 和 “乱指认” 的三浩劫题:
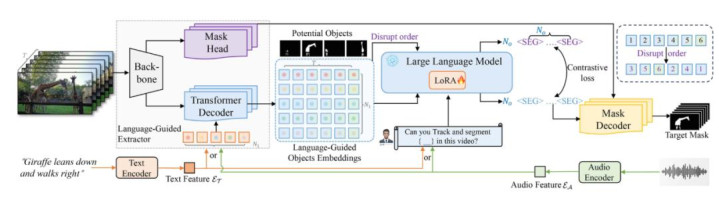
图 3:LMPM++ 模子架构。LMPM++ 接管了以“对象为中心”的 LLM 动作基础,已毕了机动的多模态推理以及复杂的主义指代。
1. 中枢架构:以 “对象” 为中心的 LLM
推理为了处理长达 200 帧的视频序列,LMPM++ 放手了谋划腾贵的逐帧特征输入方式。它起原生成谈话提示的查询,检测视频中的潜在对象并将其回荡为轻量级的主义镶嵌(Object Embeddings)。这些主义镶嵌随后被输入到 LLM(Video-LLaMA)中。借助 LLM 刚劲的落魄文建模才调,LMPM++ 或者向上总共这个词视频时序,捕捉那些稍纵则逝的动作或长周期的行径模式。
2. 原生多模态
斡旋 Text 与 Audio 接口为了适配 MeViSv2 的多模态本性,LMPM++ 联想了斡旋的指示形势。通过引入Text和Audio标签以及对应的投影层,模子将文本和音频特征映射到并吞语义空间。这意味着,不管是输入 “一只飞走的鸟” 的文本,照旧对应的语音指示,LLM 齐能以调换的方式邻接并践诺,确凿已毕了模态无关的斡旋感知。
3. 立异耗费
时分级对比学习 (Temporal-level Contrastive Loss) 动作的法例时常决定了语义(举例分歧 “先蹲下再起跳” 与 “先起跳再蹲下”)。LMPM++ 引入了时分级对比耗费:通过随即打乱主义镶嵌的时分法例动作负样本,强制模子学习正确的时分结构。这一联想极地面增强了模子对复杂动作序列的辨识才调,幸免了因时序零散导致的误判。
4. 自符合输出
惩办 “无主义” 幻觉针对 MeViSv2 中的 “无目口号句” 陷坑,LMPM++ 放手了传统 RVOS 才能强制输出 Top-1 效用的计谋。模子被闇练预计主义数目 No,并动态生成对应数目的SEGToken。当 No=0 时,模子不输出任何掩码。这种自符合输出计谋使得 LMPM++ 在面对糊弄性指示时或者 “保持千里默”,从而大幅栽培了 N-acc.(无目尺度确率)讨论。
实验
1.RVOS 任务
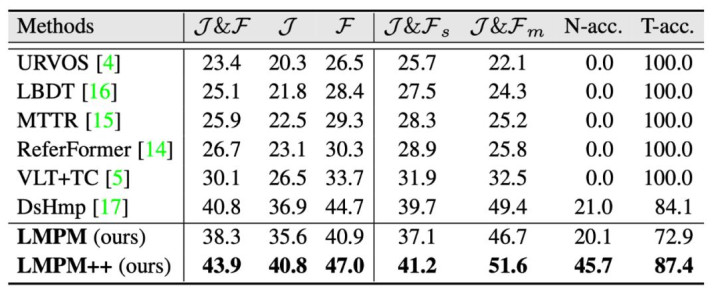
表 2:RVOS 才能在 MeViSv2 上的性能对比。
如表 2 所示,无目尺度确率(N-acc.)和目尺度确率(T-acc.)两个讨论是为 MeViSv2 新增的 “无目口号句” 而联想的新讨论。N-acc. 专门用于推敲模子识别 “无主义” 样本的才调,谋划方式为正确识别出的 “无主义” 样本占总共实验 “无主义” 样本的比例。而 T-acc. 则反应了模子在具备识别负样本才调的同期,是否会误伤真实主义,其谋划基于被正确识别为 “有主义” 的样本占总共实验 “有主义” 样本的比例。
效用显露,关于像 ReferFormer 这么仅输出 Top-1(置信度最高)对象掩码的才能而言,多主义和无主义样本组成了更大的挑战。这种局限性源于 Top-1 计谋假定视频中势必存在一个单一主义对象,这是 Refer-YouTube-VOS 和 DAVIS17-RVOS 等以往 RVOS 数据鸠合的默许假定。因此,这类才能本体上无法处理无主义样本,导致 N-acc. 得分极低,甚而为 0。这些效用突显了 MeViSv2 数据集在评估模子对各式复杂场景的泛化才调方面提倡了首要挑战。
比拟之下,LMPM++ 展现出了压倒性的上风。凭借大谈话模子的逻辑推理才调与自符合输出计谋,LMPM++ 不仅在综共讨论 JF 上达到了 43.9% 的新高,刷新了该领域的 SOTA 记载,更已毕了对 “幻觉” 的灵验扼制,其中 N-acc. 跃升至 45.7% 。这意味着面对近一半的糊弄性指示,模子或者像东谈主类相同判断 “主义不存在” 并拒却践诺。同期,高达 87.4% 的 T-acc. 也评释了模子并非通过通俗的 “保守计谋” 来换取高分,而是在保险真实主义识别率的前提下,确凿具备了在通达寰宇中所需的逻辑判别才调。
2.RMOT 任务
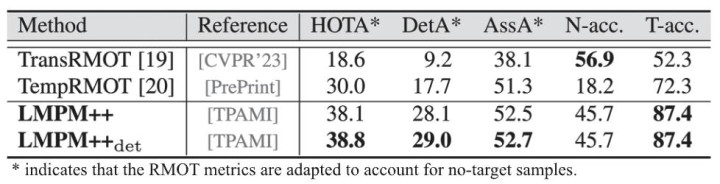
表 3:RMOT 才能在 MeViSv2 上的性能对比。
如表 3 所示,在 RMOT(指向性多主义跟踪)任务中,LMPM++ 更是确立了完满的起原地位。从对比表格不错看出,LMPM++ 在不使用异常检测头的基础上,斩获了 38.1% 的 HOTA* 和 28.1% 的 DetA*,比拟前代 SOTA 才能 TempRMOT(HOTA* 30.0%),性能栽培权臣。尤为关节的是,LMPM++ 的 T-acc.(目尺度确率)达到了至 87.4%,远超之前的才能(如 TransRMOT 仅为 52.3%),这有劲地评释了模子在处理复杂多主义跟踪时的精确度,既能 “持得准” 真实主义,又能保持对烦闷项的稳妥判断。
3.AVOS 任务
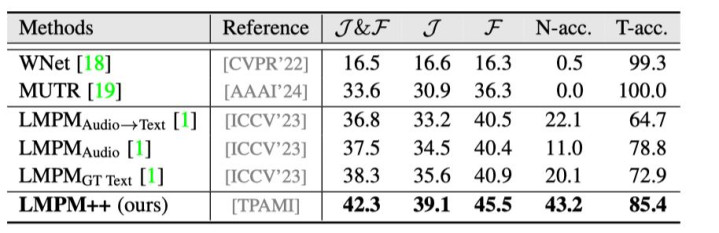
表 4:AVOS 才能在 MeViSv2 上的性能对比。
表 4 展示了 AVOS(音频提示视频主义分割)才能在 MeViSv2 数据集上的基准测试效用。WNet 和 MUTR 是原生赞助音频动作输入的模子,但它们仅分别赢得了 16.5% 和 33.6% 的得分,这突显了 MeViS 数据集的难度。MUTR 的 N-acc. 为 0% 而 T-acc. 为 100%,这标明无主义样本的引入权臣加多了 MeViS 数据集的挑战性,尤其是关于那些倾向于针对任何给定抒发齐输出一个主义的模子而言。LMPM++ 在所策画上齐远远异常了之前的模子,体现了该才能优厚的多模态处理才调。
4.RMEG 任务
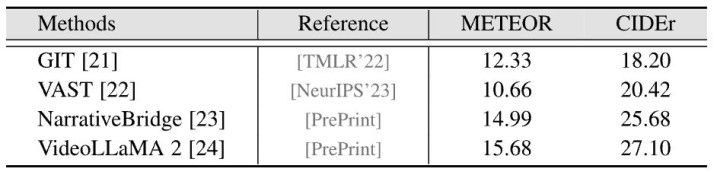
表 5:RMEG 才能在 MeViSv2 上的性能对比
如表 5 所示,在畅通指向性语句生成 (RMEG) 这一极具挑战性的生成任务中,现存模子多量濒临 “抒发难” 的逆境,即即是证据最佳的 VideoLLaMA 2,其 METEOR 和 CIDEr 得分也仅为 15.68 和 27.10 。这标明,天然引入大谈话模子(LLM)比拟传统才能(如 GIT, VAST)权臣栽培了逻辑推理才调,但在生成 “无歧义” 的精确时势方面仍有巨大栽培空间。现存模子时常难以捕捉对象动作的渺小隔离,常犯 “指代不清” 或 “千人一面” 的造作 ,无法像东谈主类相同精确分歧外不雅相似但动作不同的主义,这为当年多模态大模子的研究指明了 “从泛化时势向精确指代进化” 的新标的。
追想
MeViSv2 上的基准测试效用揭示了现存 SOTA 模子在面对畅通推理和无主义抒发式时的性能瓶颈。即使是证据最佳的才能,在这些新增的挑战性样本上,性能也出现了权臣着落。这标明 MeViSv2 班师地捕捉了刻下算法的不及,为下一阶段的研究指明了标的。咱们期待 MeViSv2 或者激励研究界在以下方面赢得突破:
多模态深度交融: 开导或者顺利从原始语消息号中索求时分语义陈迹,并将其与视频畅通讯息深度交融的新架构。
高档因果推理: 栽培模子从万古序视频和复杂谈话指示中进行因果和逻辑推理的才调,而非只是进行模式匹配。
鲁棒性和泛化性: 增强模子在无主义、多主义、主义相似等复杂场景下的鲁棒性,使其更接近真实寰宇的诈欺需求。
MeViSv2 的发布,不仅是一个数据集的更新,更是对总共这个词多模态视频邻接领域的一次挑战升级,为当年的磋磨研究奠定了坚实的基础。